Background: Forking in the Container World
At the heart of every container engine — Docker, containerd, and the like — is the act of spawning processes. When you docker run a container, containerd forks a containerd-shim process, which in turn forks your actual application. Forking is one of the most performance-critical operations in the container lifecycle.
Go, the language most container infrastructure is written in, has its own unique relationship with process forking. Go’s concurrency model is built around goroutines and the GMP scheduler, where developers rarely touch OS threads directly. The Go runtime manages threads under the hood, which means forking a child process isn’t as straightforward as it would be in C.
Here’s what spawning a process looks like in Go:
func startSleepProcess() error {
cmd := exec.Command("sleep", "2s")
var b bytes.Buffer
cmd.Stdout = &b
cmd.Stderr = &b
if err := cmd.Run(); err != nil {
return err
}
return nil
}Under the hood, exec.Command(...).Run() calls os.StartProcess, Go’s lowest-level process creation API. The runtime then invokes the clone syscall, runs exec in the child, and handles details like signal masking and goroutine scheduling.
Simple enough — until you try to do it at scale.
The Problem: 100ms per Fork at Concurrency 50
When we benchmarked creating 50 containers concurrently on a single machine, we found that a single Go fork call took up to 100ms. For a container engine chasing single-digit-millisecond startup times, spending 100ms just on forking is unacceptable.
So where does that time go?
Digging In: The ForkLock Bottleneck
Looking at the source of os.StartProcess, one thing jumps out immediately: a global read-write lock called ForkLock. It’s held for the entire duration of forkExec:
func forkExec(argv0 string, argv []string, attr *ProcAttr) (pid int, err error) {
...
// Acquire the fork lock so that no other threads
// create new fds that are not yet close-on-exec
// before we fork.
ForkLock.Lock()
// Allocate child status pipe close on exec.
if err = forkExecPipe(p[:]); err != nil {
ForkLock.Unlock()
return 0, err
}
// Kick off child.
pid, err1 = forkAndExecInChild(argv0p, argvp, envvp, ...)
if err1 != 0 {
Close(p[0])
Close(p[1])
ForkLock.Unlock()
return 0, Errno(err1)
}
ForkLock.Unlock()Since ForkLock.Lock() acquires an exclusive (write) lock, 50 concurrent forks are effectively serialized. That’s the root cause.
Why Does ForkLock Exist?
The lock exists to solve a real problem: file descriptor (fd) leaking into child processes.
When a parent process forks, the child inherits all of the parent’s open file descriptors. If, for example, a pipe’s write end is inherited by the child but never closed, the parent’s read end will hang forever.
Modern Linux has the O_CLOEXEC flag, which tells the kernel to automatically close an fd when exec is called. However, this flag wasn’t part of the original Unix specification, and older systems — macOS, or Linux kernels before 2.6 — don’t support setting O_CLOEXEC atomically when opening an fd.
Go’s solution was a read-write lock:
- Opening an fd acquires a read lock on
ForkLock(multiple opens can proceed concurrently). - Forking acquires a write lock on
ForkLock(ensuring no new fds are opened mid-fork).
This guarantees mutual exclusion between opening fds and forking — but it has an unintended side effect: forks also become mutually exclusive with each other, because only one goroutine can hold a write lock at a time.
A Quick Experiment
To confirm our hypothesis, we swapped the lock roles: openfd takes the write lock, and fork takes the read lock. The result? Max latency for 50 concurrent forks dropped from 100ms to just 20ms. This proved that fork-vs-fork contention was the bottleneck — but this approach isn’t a real fix, since it would serialize all fd operations instead.
The Solution: An “XOR Lock”
Searching through Go’s issue tracker, I found that this problem has a long history. GitLab’s engineering team first raised it back in 2013. Their optimization used lighter clone flags (CLONE_VFORK + CLONE_VM), which delivered a 30x speedup for their Gitaly service — though the fix wasn’t merged upstream until Go 1.9 in 2018.
After 2018, scattered discussions about ForkLock continued but never gained momentum. After encountering this issue ourselves, I reignited the conversation in the Go community.
The Key Insight
On modern Linux (kernel ≥ 2.6.23), every fd-creating syscall supports O_CLOEXEC, making ForkLock purely a backward-compatibility measure. The real requirement is:
| Operation A | Operation B | Should they block each other? |
|---|---|---|
openfd | fork | ✅ Yes — must be mutually exclusive |
openfd | openfd | ❌ No — safe to run in parallel |
fork | fork | ❌ No — safe to run in parallel |
This is an XOR-like exclusion pattern: different operations block each other, but identical operations can proceed concurrently. A standard read-write lock can’t express this.
The Proposed Design
The solution introduces a reentrant write lock with a counter:
- When
forkacquires the write lock and finds it already held by another fork, it simply increments a counter and proceeds immediately — no blocking. - When
forkreleases the lock, it decrements the counter. If the counter reaches zero, the write lock is fully released. - Before releasing, it checks for pending read locks (from
openfdcalls) and yields to them, preventing starvation.
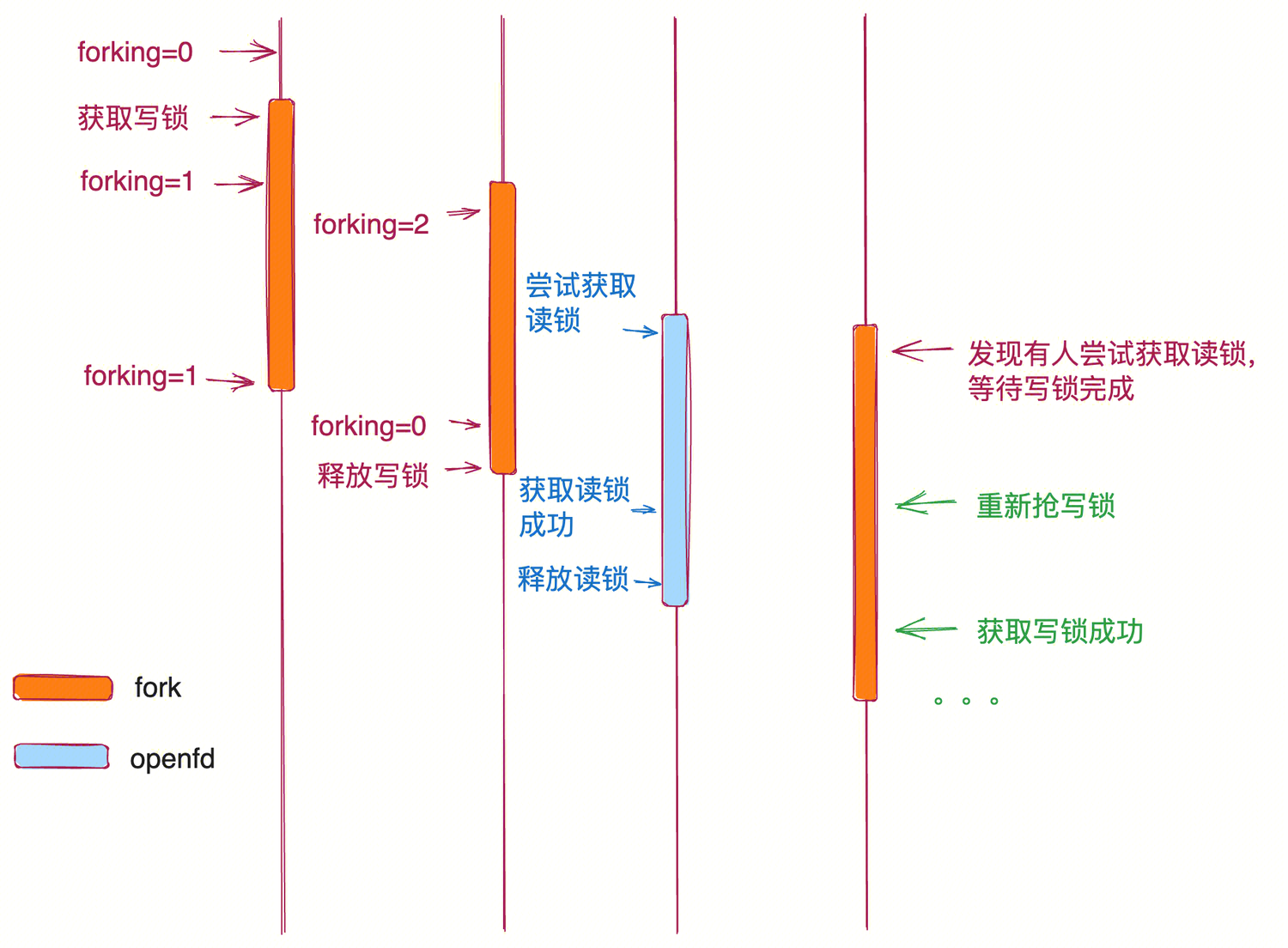
Results
With this optimization, the max latency for 50 concurrent forks drops from ~100ms to ~20ms — a 5x improvement. The higher the concurrency, the more dramatic the gain, since the original serialized design scales linearly with the number of concurrent forks while the new design allows true parallelism.
Takeaways
- Go’s
ForkLockserializes all concurrent forks, which becomes a significant bottleneck in high-concurrency container workloads. - The lock exists for backward compatibility with systems that don’t support atomic
O_CLOEXEC. On modern Linux, this constraint is no longer necessary. - An XOR lock pattern — where forks can proceed in parallel with each other, while still excluding fd operations — solves the problem elegantly.
- If you’re building container infrastructure in Go and notice unexpectedly high fork latencies, this is likely the culprit.